Machine Learning Systems: Security
February 03, 2021
The security of Machine Learning models is a consideration that we often omit to study thoroughly when we are designing Machine Learning Systems. Yet, it presents a risk that is growing with the increase of AI adoption rate.
In this post I’ll go over the main concepts to understand this subject:
- Why do we need to care about the security of ML systems ?
- What are the vulnerabilities of ML systems ?
- How can we secure ML Systems ?
Why should we care ?
Machine Learning models are more and more integrated in sensitive decision-making systems such as autonomous vehicles, health diagnosis, credit scoring, recruitment, etc. Some models can be trained on personal data like private emails, photos and messages from social media.
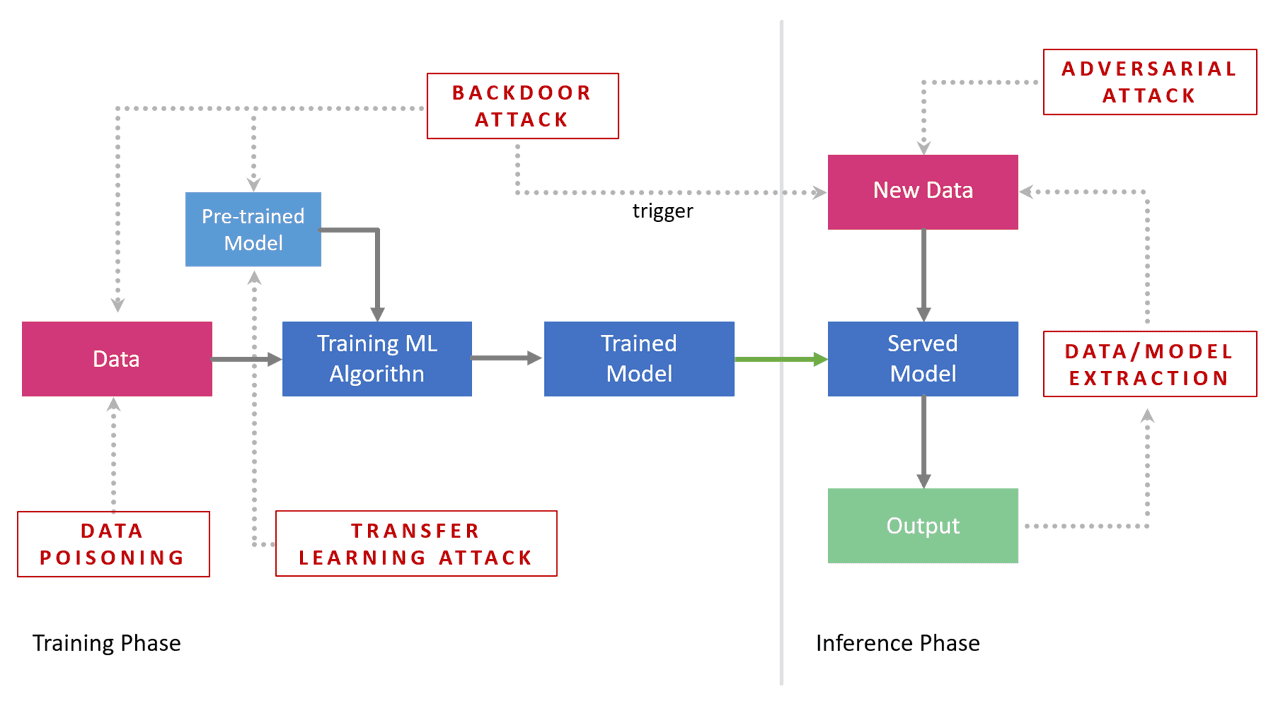
Machine learning models are complex software components and can be compromised. Vulnerable systems can lead to:
- Data extraction: the exposure of sensitive information or specific details included in the data used for training the models.
- Model extraction: copying a model by stealing the internal parameters and hyperparameters.
- Model tricking: fooling the model by manipulating the inputs, leading to erroneous decisions.
- Model corruption: methods that perturb the inner functioning of the model to generate corrupted outputs.
What are the threats ?
Here is a list of some vulnerabilities from which ML models suffer, this is a non-exhaustive list:
Data extraction
-
Unintended Memorization
Deep learning models and in particular generative models suffer from unintended memorization1, they can memorize rare details from the training data. Using only inferences from the model, it is possible to extract sensitive information from the training dataset.
This method was used to extract credit card details and social security numbers from Gmail’s Smart Compose feature that helps you to write emails faster.
-
Membership Inference
Using this technique an attacker can infer whether a new data record is included in the training dataset or not.
Model extraction
-
Model Stealing
Using these methods and by querying models (with predictions APIs), it is possible to extract an equivalent ML model. These attacks are successful against a wide variety of model types: logistic regressions, decision trees, SVMs and deep neural networks.
A set of model extraction attacks were used to steal model types and parameters from public machine learning services such as BigML and Amazon Machine Learning in 2016 2.
Model tricking
-
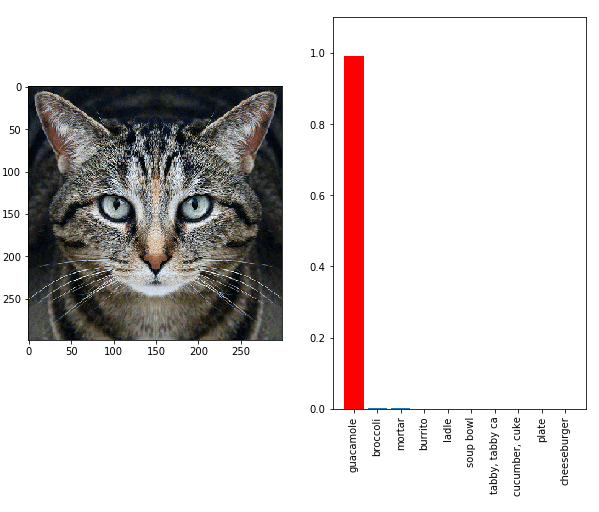
Adversarial attacks
Adversarial attack is maybe one of the most known attacks on deep neural networks since it has been widely mediatized. It works by providing deceptive input at inference time. It’s a powerful method because the noise added to the input can be imperceptible and it does not depend on the architecture of the attacked model.
In the following example 3, the model is tricked to classify the image as “guacamole”.
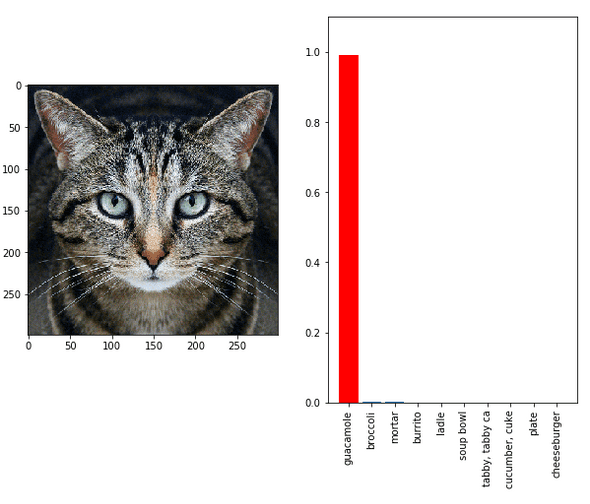
Adversarial attack: cat recognized as guacamole
Model corruption
-
Data Poisoning
Training data often include information harvested by automated scrapers or from unverified sources on the web, this is a vulnerability that can be exploited to tamper with models.
For example, data poisoning was used to generate undetectable spam messages 4.
-
Backdoor attacks
These methods work by injecting a trojan in the training data or in a pre-trained model that is activated by a trigger at inference time to make the model output a specific result. It is model-agnostic.
In this example the trigger is a small square patch or sticker that is used to flip the identification of the stop sign 5.

Backdoor attack: green square patch on stop sign -
Attacks on Transfer Learning
If a pre-trained model is corrupted with data poisoning or a backdoor attack, it is likely that a new model that is trained using the corrupted model as a starting point will be corrupted as well.
Federated Learning, considering its distributed nature, can be even more exposed to Model corruption through training data manipulation as we can assume that an ML hacker has a full control of part of the training samples and labels. Federated learning can also be subject to data extraction attacks through the leakage of gradients shared between the workers and/or the server 6.
How can we secure models ?
Machine Learning security is an active research area, and since we are dealing with computer systems we cannot have a 100% secure system. Some of the defense mechanisms that exist are only experimentally validated, so we have to be aware that they can be broken.
-
Differential Privacy
Differential Privacy can be used against data extraction attacks. The aim of this technique, applied during the training of the model, is to approach similar outputs when the training is done with the sensitive data or without it. It tries to ensures that the model does not rely too much on individual samples 1. In practice, that comes at the expense of accuracy.
-
Homomorphic encryption
Homomorphic encryption is an encryption method that enables computations on encrypted data directly. It ensures that the decrypted result is the same as if the computation had been done on unencrypted inputs. In a simplified way, for an encryption function :
It is one of the defense mechanisms used in Federated learning.
-
Randomization methods
The goal of these techniques is to protect Deep Neural Networks models against perturbations by adding randomness to test points and using the fact that Deep Neural Networks are robust to random perturbations. A random input transformation can help mitigate adversarial effects. Random smoothing technique is used to perturb backdoor attack triggers 7.
-
Input Preprocessing
Input preprocessing can be used against backdoor attacks or adversarial attacks, by modifying the model input during training or testing. Autoencoders can be used to clean the input. An imperfect reconstruction can make the model unable to recognize triggers 7.
-
Adversarial training
In this method, we train the model by adding adversarial samples in the training data to improve its robustness against adversarial attacks 8.
Conclusion
Machine Learning systems are complex software systems where software code and data are interlaced, so they do not only face computer security risks but also data threats. Data Scientists and ML Engineers need to be aware of these risks when they design their Machine Learning systems.
References
-
The Secret Sharer: Evaluating and Testing Unintended Memorization in Neural Networks
-
Fooling Neural Networks in the Physical World with 3D Adversarial Objects
-
BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain
-
Dataset Security for Machine Learning: Data Poisoning,Backdoor Attacks, and Defenses