AI Systems Security: Top Tools for Preventing Prompt Injection
August 10, 2024
This is the third article in my series on AI privacy and security. The first article covered various AI vulnerabilities, and the second addressed an example of privacy risks in LLMs. Now, we turn to solutions, specifically tools to detect and counter prompt injection attacks in LLMs.
Prompt injection has been identified as the leading risk in the OWASP Top 10 for LLM and generative AI applications, highlighting the urgent need for effective defenses.
Governments around the world are taking action to secure AI. The White House has issued an Executive Order on AI security, and agencies like CISA and the UK’s NCSC have released new guidelines for secure AI development. Additionally, the EU AI Act’s Article 15 requires high-risk AI systems to be resistant to attacks, pushing for stricter security measures.
In this article, we will introduce open-source tools to help protect your AI systems from these threats.
Prompt Injection Risks
Prompt Injection occurs when an attacker manipulates a large language model (LLM) with crafted inputs, causing it to perform unintended actions.
This can be done through direct prompt injections, where the attacker alters the system’s prompt, or indirect injections, where malicious prompts are embedded in external content processed by the LLM.
Successful attacks can lead to:
- Sensitive data leaks: For example, exploiting a feedback form processed by the LLM to exfiltrate sensitive information like passwords or personal data posted by other users.
- Altered decision-making process: A candidate uploads a resume with hidden instructions, causing the LLM to falsely rate it as excellent.
- Unintended actions: If the LLM is connected to additional tools such as databases or APIs, it can be tricked into unauthorized usage of these tools.
Prevention Measures for Prompt Injection
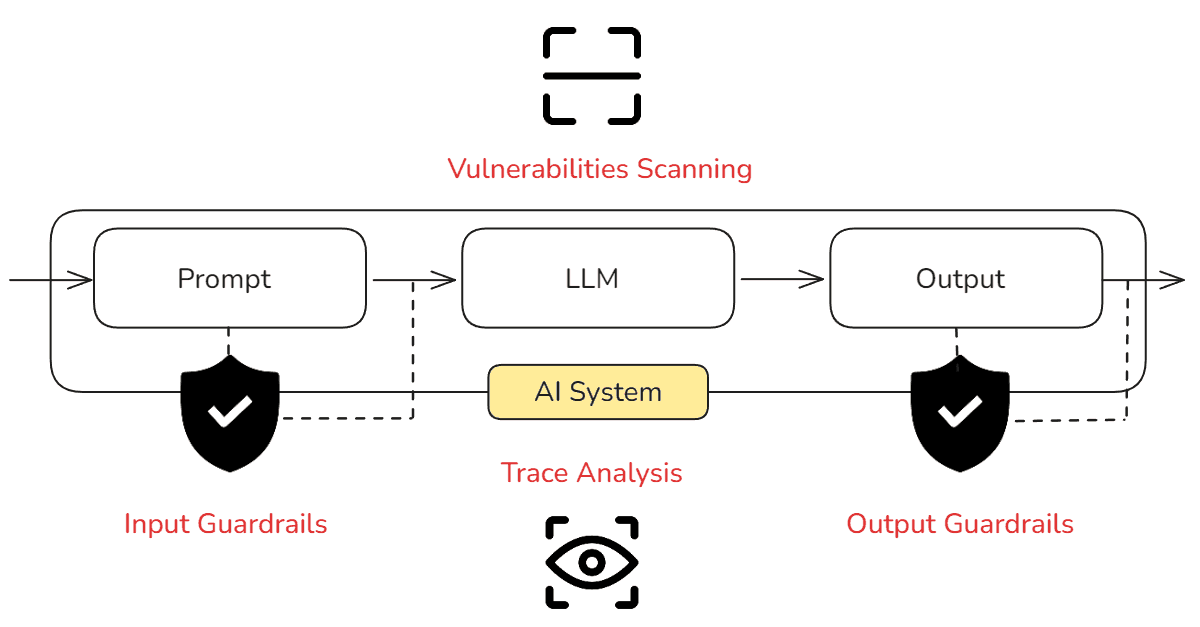
There are several measures that can be implemented to prevent this kind of attacks, including:
1. General Security Practices:
- Access Controls and Authentication: Restrict LLM access to authorized users only.
- Secure Deployment: Use network segmentation and firewalls to secure the LLM infrastructure.
- Monitoring and Alerting: Set up systems to detect and respond to unusual behavior.
2. LLM-Specific Security Practices:
- Input Validation and Sanitization: Ensure all inputs are validated and sanitized to remove malicious content.
- Implementing Guardrails: Detect and mitigate the presence of specific types of risks in inputs and outputs.
- Security Audits and Red Teaming: Regularly conduct security audits and penetration tests to identify and address vulnerabilities.
In the rest of this article, we will focus on the LLM-Specific measures and explore tools that can help scan for and prevent prompt injections.
Useful Open-Source Tools
Here is a non-exhaustive list of open-source tools that can help secure your AI systems as of August 2024.
1. Stresstesting: Vulnerability Scanners
-
A Python library that automatically detects performance, bias & security issues in AI applications by scanning your models or systems for issues.
-
A command-line tool that scans for hallucination, data leakage, prompt injection, misinformation, toxicity generation, jailbreaks, and other weaknesses.
-
PyRIT (by Microsoft)
PyRIT is a library developed by the Microsoft AI Red Team, for researchers and engineers to help them assess the robustness of their LLM applications against different harm categories. It allows to automate AI Red Teaming tasks.
2. Implementing Guardrails
-
NeMo-Guardrails (by Nvidia)
A Python toolkit to add “programmable guardrails” to LLM-based conversational applications.
-
A Python library that parses Input/Output to detect risks in AI application. It has a large collection of pre-built measures of various types of risks.
-
A Python library for sanitization, detection of harmful language, prevention of data leakage, and resistance against prompt injection attacks.
3. Monitoring: Trace Analysis
-
This library, built by a top-notch team of researchers in AI privacy and security, is a trace scanner for LLM-based AI agents designed to detect bugs and security threats, such as data leaks, prompt injections, and unsafe code execution.
Conclusion
In conclusion, Red Teaming AI systems against prompt injection attacks is crucial, but it’s only part of the broader security landscape. The tools we’ve covered can be combined to strengthen defenses (you can find some examples in the references), but true security requires addressing other risks, like data poisoning during training or fine-tuning.
AI security is an ongoing effort—attackers evolve, so your defenses must too. Regular updates and vigilance reduce risks but don’t guarantee immunity. By using these tools and staying proactive, we can enhance our AI system’s resilience against emerging threats.
References
- LLM Security Guide - Understanding the Risks of Prompt Injections and Other Attacks on Large Language Models
- How to implement LLM guardrails
- Red Teaming AI: A Closer Look at PyRIT
- Automatic generation of LLM guardrails with NeMo and Giskard
- Guardrails for LLMs: a tooling comparison
- The Best LLM Safety-Net to Date
- Machine Learning Systems: Security